얼마 전 프로젝트를 둘러보다가 언제부턴가 생겨난 거대 클래스를 발견했습니다. 이 거대 클래스에는 서로 연관성이 적은 필드와 메서드가 한 클래스 안에 묶여 있었습니다. 메서드 목록을 정리해서 분석해보니, 역시 서로 다른 책임 4가지를 가지고 있는 클래스였습니다. 이 클래스는 4개의 클래스로 분리되었습니다.
작업을 하고 나서 <레거시 코드 활용 전략> 책을 보니 비슷한 기법에 대한 소개가 있었습니다. 그래서 거대 클래스의 진짜 책임을 찾고 그 외의 책임을 분리하는 방법을 제 경험과 <레거시 코드 활용 전략>의 내용을 엮어 소개해보려고 합니다.
서비스의 복잡한 로직을 다루다 보면 비슷한 데이터를 다루는 함수가 생겨납니다. 관련성 있는 데이터와 함수는 하나로 묶어 두는 것이 좋습니다.
함수와 데이터를 하나로 묶기 위해 클래스를 사용할 수 있습니다. 데이터와 함수를 각각 클래스의 필드와 메서드로 묶으면, 데이터에 대한 응집도가 높아지고 값과 함수를 한 곳에서 관리할 수 있어 데이터와 관련된 함수를 찾기도 편합니다. 나중에 이 데이터와 관련된 기능을 추가해야 한다면 기능을 추가할 적절한 위치를 찾아내기도 편할 것입니다.
클래스를 사용할 때 주의할 점은 그 클래스의 책임을 분명히 해야 한다는 것입니다. 클래스가 단 하나의 책임을 가지지 않고 포괄적인 책임을 가지고 있다면 아주 작은 유사점을 가진 데이터나 함수도 그 클래스로 모이게 되고, 결국 무슨 일을 하는지 알 수 없는 거대한 괴물 클래스가 되고 맙니다.
이 글에서는 너무 많은 책임을 맡아버린 불쌍한 거대 클래스의 진짜 책임을 찾아주는 방법을 소개합니다. 클래스가 정말로 해야 하는 일을 찾기 위해 클래스가 지금 맡고 있는 모든 책임을 분석해 보겠습니다.
클래스의 책임 파악하기
SOLID 원칙 중 하나인 단일 책임 원칙(SRP, Single Responsibility Principle)에 따라, 하나의 클래스는 단 하나의 책임만 가져야 합니다.
이를 지키지 않으면 클래스가 하는 일이 너무 많아지고 책임이 모호해져 기능을 추가하거나 수정할 때 어떤 영향이 있을지 감지하기 매우 어려워집니다. 리팩터링을 수행하거나 단위 테스트를 추가하기도 어려워지고, 따라서 많은 버그를 동반하게 됩니다.
클래스에 필드와 메서드가 너무 많다면 그 클래스는 분명 한 가지 책임만 가지고 있는 게 아닐 겁니다. 클래스의 책임을 줄이기 위해 클래스가 어느 순간부터 떠맡게 된 책임을 찾아서 적절한 곳으로 옮겨 줘야 합니다.
그러기 위해 가장 먼저 해야 할 일은 클래스가 가진 역할을 파악하는 것입니다. 클래스의 역할을 파악하기 위해 아래와 같은 방법을 시도해 볼 수 있습니다.
메서드 그루핑
메서드는 그 클래스가 만드는 인스턴스가 할 수 있는 ‘행동’을 나타냅니다. 인스턴스가 어떤 식으로 행동하는지 안다면, 클래스가 무슨 역할을 하고 있는지 파악할 수 있습니다.
예시로, 아래와 같은 클래스가 있다고 가정해보겠습니다.
1class LargeClass {2 private a: string;3 private b: B;4 private c: C;56 public getA(): void { /**/ }7 public getB(): void { /**/ }8 public doSomethingWithA(): string { /**/ }9 public async fetchC(): Promise<C> { /**/ }10 public changeValueOfB: void (val: number) { /**/ }11}
메서드를 그룹으로 묶기 전에, 클래스에 어떤 메서드가 있는지 파악해야 합니다. 우선 문법 하이라이트가 가능한 문서 작성 프로그램 혹은 IDE에 클래스의 모든 메서드 선언부를 붙여 넣습니다. 붙여넣을 때 접근제어자, 메서드 이름, 매개변수, 반환 값을 모두 포함해서 리스팅합니다.
1 public getA(): void;2 public getB(): void;3 public doSomethingWithA(): string;4 public async fetchC(): Promise<C>;5 public changeValueOfB: void (val: number);
💡 메서드 줄의 위치를 많이 이동시켜야 하므로 단축키로 줄을 이동할 수 있는 IDE에서 수행하는 게 편합니다.
💡 메서드 이름이 잘 지어졌다면 메서드 이름만 보고도 그 메서드가 하는 일을 알 수 있을 것입니다. 만약 메서드 이름만으로 파악하기 어렵다면, 일단 그 메서드에 대한 리팩터링을 먼저 수행하는 게 좋습니다.
메서드 선언 리스트를 훑어보면서 메서드 이름에 들어가는 명사가 겹치는 메서드를 찾습니다. 이들을 비슷한 위치로 이동시켜서 비슷한 위치에 메서드가 모이도록 합니다.
1 /** A **/2 public getA(): void;3 public doSomethingWithA(): string;45 /** B **/6 public getB(): void;7 public changeValueOfB: void (val: number);89 /** C **/10 public async fetchC(): Promise<C>;
메서드를 이동시키다 보면 그룹이 몇 개 만들어지는데, 그 그룹에서 공통되게 사용하는 필드나 데이터를 찾을 수 있을 것입니다. 이것이 이 클래스가 수행하고 있는 하나의 역할이 됩니다.
모든 메서드를 그루핑했다면 클래스의 모든 책임을 찾을 수 있을 것입니다. 위의 예시 클래스의 경우에는 아래와 같은 책임이 있다고 볼 수 있습니다.
- a라는 이름의 string 값을 관리
- B라는 이름의 클래스의 인스턴스를 관리
- C라는 이름의 클래스의 인스턴스 값을 어디선가 가져오기
특징 스케치
만약 하나의 메서드 안에서 두 개 이상의 데이터를 참조하거나 수정하는 경우가 많다면, 메서드 그루핑을 수행하기는 어려울 수 있습니다. 그럴 때 특징 스케칭을 수행해 볼 수 있습니다.
- 각 인스턴스 변수 하나당 원 하나를 그린다.
- 메서드를 위한 원을 각각 그린다.
- 메서드에서부터 인스턴스 변수로 향하는 선을 긋는다.
- 그러면 클러스터링을 할 수 있는 구간을 발견할 수 있다. 이런 클러스터를 자체 클래스로 만드는 것을 고려해본다.
예시
예약을 관리하는 아래와 같은 클래스가 있다고 가정해 보겠습니다.
1class Reservation {2 date: Date;3 seat: Seat;4 customer: Customer;5 coupons: Coupon[];67 public changeDate(changedDate: Date) {}89 public changeSeat(changedSeat: Seat) {}1011 public getTotalFee(): number {12 return this.getTotalFee() - this.getDiscount();13 }1415 private getTicketFee() {16 /** 계산식 **/17 }1819 public addCoupon(coupon: Coupon) {20 this.coupons.push(coupon);21 }2223 private getDiscount(): number {24 return this.coupons.reduce((pre, coupon) => pre + coupon.amount, 0);25 }26}
이 클래스에서 특징 스케치를 수행해보겠습니다. 먼저 클래스가 가진 필드를 그렸습니다.
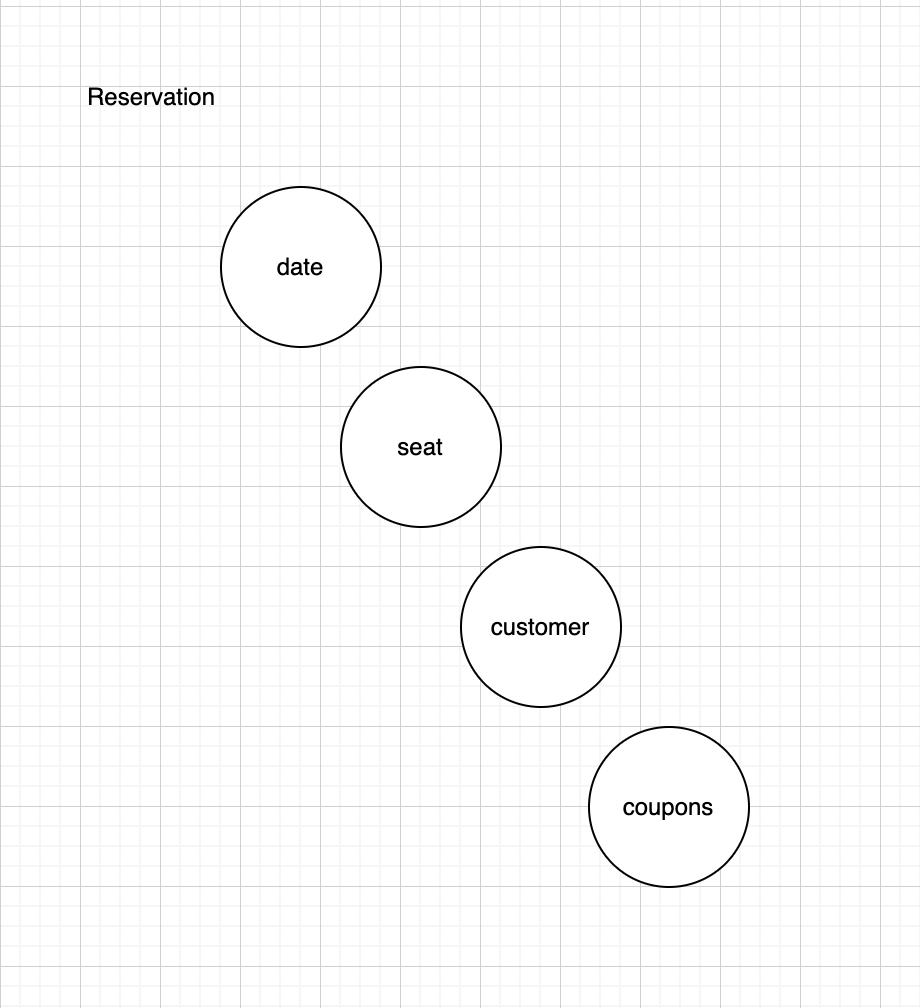
그 다음, 클래스가 가진 메서드를 그립니다. 메서드가 접근하는 필드를 선으로 나타냅니다.
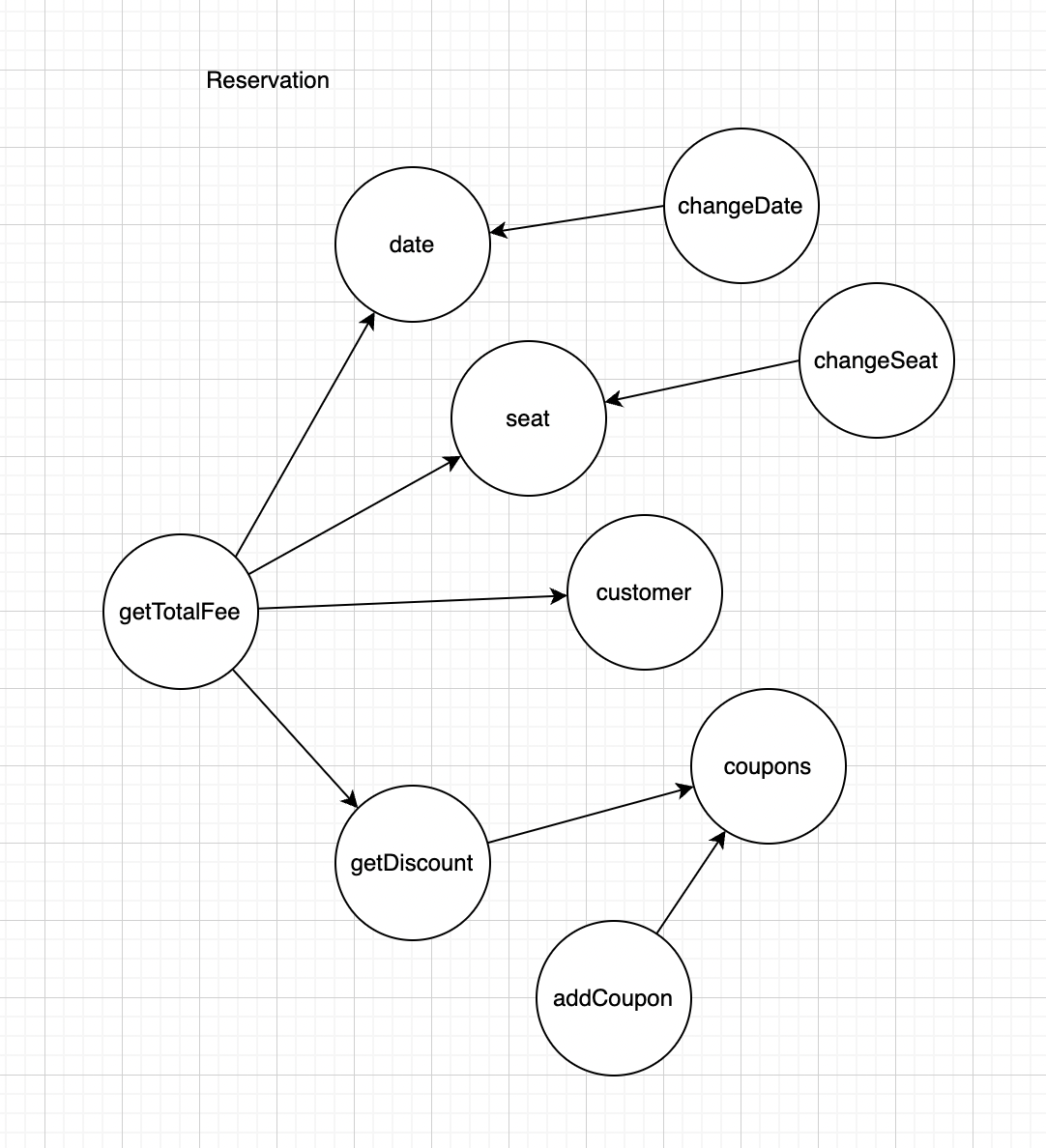
그러면 아래와 같은 클러스터를 발견할 수 있습니다.
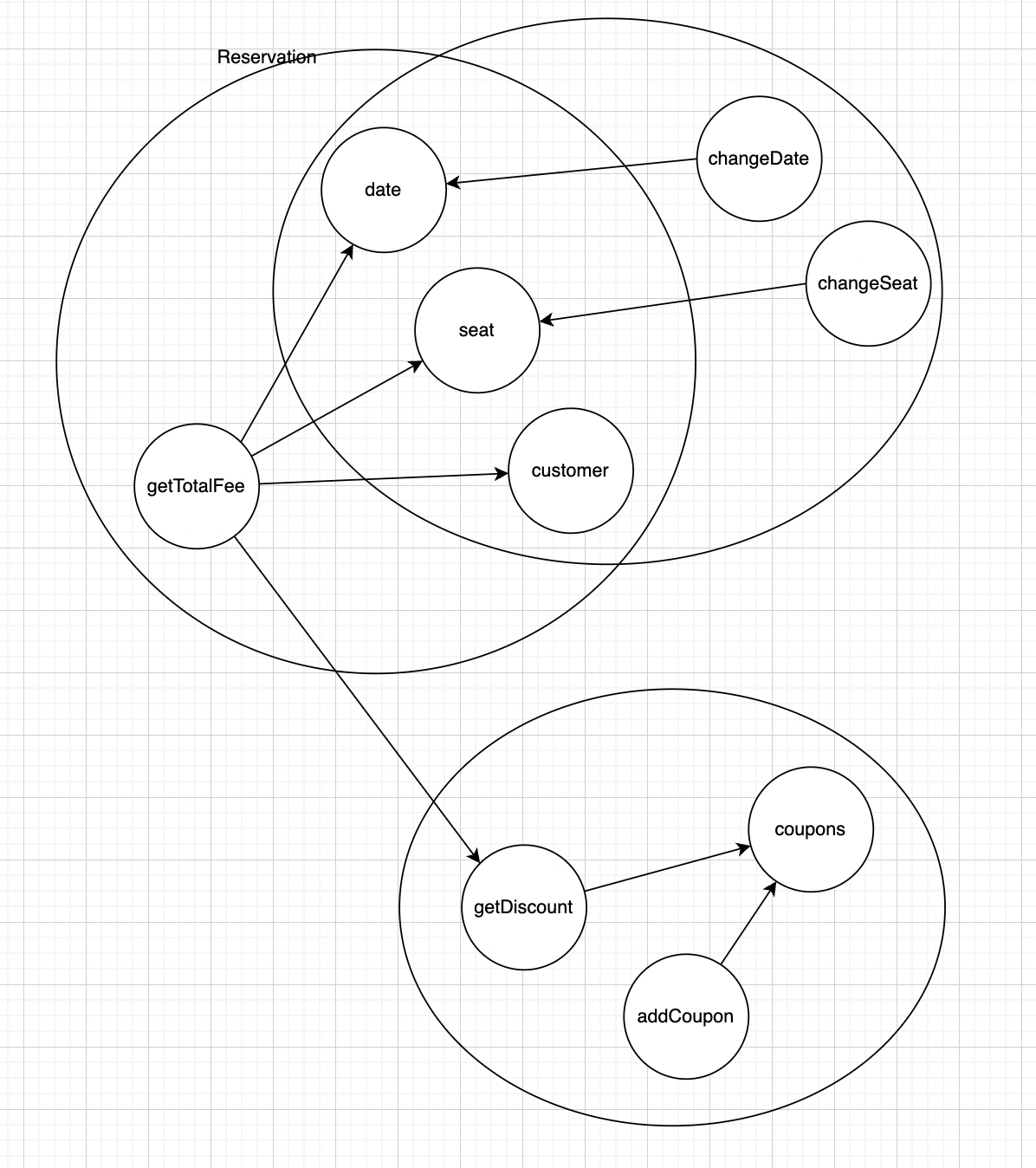
특징 스케치를 통해, Reservation 클래스의 책임 몇 가지를 발견했습니다.
- 예약 정보를 관리한다
- 예약의 총 요금을 계산한다
- 예약에 적용된 쿠폰으로 할인된 가격을 계산한다
Reservation 클래스의 진짜 책임은 예약 정보를 관리하는 것입니다. 따라서, 예약의 총 요금을 계산하고 할인된 가격을 계산하는 책임은 다른 클래스에 위임할 수 있습니다.
스크래치 리팩터링
만약 코드가 너무 복잡해서 구조를 이해하지 못해 위의 방법을 수행하기 어렵다면, 일단 리팩터링을 수행해 보는 것도 좋습니다. 코드를 이해하는 데는 스크래치 리팩터링 방법이 큰 도움이 됩니다.
스크래치 리팩터링은 테스트 루틴을 신경 쓰지 않고 마음껏 리팩터링을 수행해 본 다음 모든 변경 사항을 폐기합니다. 따라서 코드에 반영하기 위한 것이 아니라 오직 작업자가 코드를 이해하기 위한 리팩터링입니다.
리팩터링을 수행하다 보면 코드에 대한 이해가 깊어져 그 클래스가 가진 책임을 발견해낼 수도 있고, 위에서 소개한 방법을 수행할 힌트를 얻을 수도 있습니다.
클래스 분리하기
메서드 그루핑이나 특징 스케치를 통해 묶인 필드와 메서드가 있다면, 이들을 클래스로 분리해내 책임을 분리할 수 있습니다.
클래스 추출하기
클래스 내에 묶을만한 데이터와 메서드가 있다면, 이들을 클래스로 추출해 분리할 수 있습니다. 그리고 원래 클래스에서 추출한 클래스의 인스턴스를 생성하고, 필요할 때 인스턴스의 메서드를 호출하는 방식으로 리팩터링할 수 있습니다.
마틴 파울러가 <리팩터링 2판>에서 소개하는 “클래스 추출하기” 절차를 요약하면 다음과 같습니다.
- 특정 데이터나 메서드를 묶어서 클래스로 분리
- 분리한 클래스의 인스턴스를 생성자에서 생성
- 필요할 때 인스턴스의 메서드를 호출하는 방식으로 사용
이렇게 하면 거대 클래스가 가지고 있던 수많은 책임을 작은 클래스들에게 나누어 줄 수 있습니다. 거대 클래스는 이 작은 클래스들의 프론트엔드로서 행동하게 됩니다. 즉, 클라이언트로부터 받은 요청을 작은 클래스에게 전달하는 역할을 하게 됩니다.
인터페이스 분리 법칙 활용
클래스를 추출해서 책임을 위임하면 단일 책임 원칙을 지키도록 할 수는 있지만, 밖으로 공개되는 메서드의 수는 여전히 많은 상태입니다. 필요에 따라 일부 메서드만 공개하도록 하기 위해 인터페이스를 분리할 수 있습니다.
메서드를 아주 많이 가지고 있는 클래스가 있을 때, 모든 클라이언트가 그 클래스의 모든 메서드를 사용하는 경우는 매우 드뭅니다. 특정 클라이언트가 사용하는 메서드들을 모아서 하나의 인터페이스를 생성하고, 클래스가 이 인터페이스를 구현하도록 해서 인터페이스를 분리할 수 있습니다.
그러면 클라이언트들은 특정 인터페이스를 통해서만 클래스를 볼 수 있습니다. 이렇게 되면 클래스가 가지고 있는 다른 정보는 감추고 클라이언트와의 의존 관계를 줄일 수 있습니다.
결론
복잡해진 지 얼마 되지 않아 책임 간의 복잡도가 높지 않은 클래스는 메서드 그루핑과 클래스 추출을 통해 비교적 간단하게 책임을 분리할 수 있습니다. 그러나 클래스 내의 책임이 복잡하게 얽히기 시작하면 특징 스케치나 스크래치 리팩터링을 수행해 우선 클래스의 동작을 이해해야 하고, 책임을 완전히 떼내는 것도 어려웠습니다.

거대 클래스가 생겨나는 낌새를 눈치채지 못하고 방치해두다 보면, 손 쓰기도 어려울 정도로 골치 아픈 괴물 클래스가 탄생해버립니다. 이 괴물 클래스는 보기에만 복잡해 보이는 게 아니라 살짝만 건드려도 버그를 만들어내는 골칫거리가 되고 맙니다.
너무 복잡해서 손 쓸 방법이 없어 보이는 클래스라도, 지금 수정하지 않는다면 다음 주쯤엔 더 복잡해져 있을 수도 있습니다. 그러니 점점 복잡해지고 있는 클래스를 발견한다면 그 책임을 파악해 적당히 나눠주는 것이 좋습니다.
변경을 기피하는 노력은 또 다른 나쁜 결과를 초래한다. 사람들이 자기가 가진 기술을 변경시키지 않으면 그 기술은 녹슬게 마련이다. 실제로 일주일에 여러 번 수행하지 않는다면 하나의 큰 클래스를 여러 개로 나누는 일을 매우 복잡한 일이 될 것이다. 하지만 꾸준히 한다면 그 일은 일상적인 일이 될 것이다. 여러분은 무엇을 나누고 무엇을 나누지 않을지에 대해 점점 더 분명히 알게 될 것이고, 그런 결정은 점점 더 쉬운 일이 된다.
- <레거시 코드 활용 전략>, 마이클 C. 페더스
참고
- <레거시 코드 활용 전략>, 마이클 C. 페더스 저 / 이우영, 고재한 공역 / 에이콘출판사 / 2008
- <리팩터링 2판>, 마틴 파울러 저 / 개앞맵시, 남기혁 역 / 한빛미디어 / 2020
